Data Preparation for Machine Learning
2 minutos de lecturaA partir del dataset https://archive.ics.uci.edu/ml/datasets/Poker+Hand vamos a realizar un algoritmo que sea capaz de clasificar las diez manos posibles del poker.
Dataset
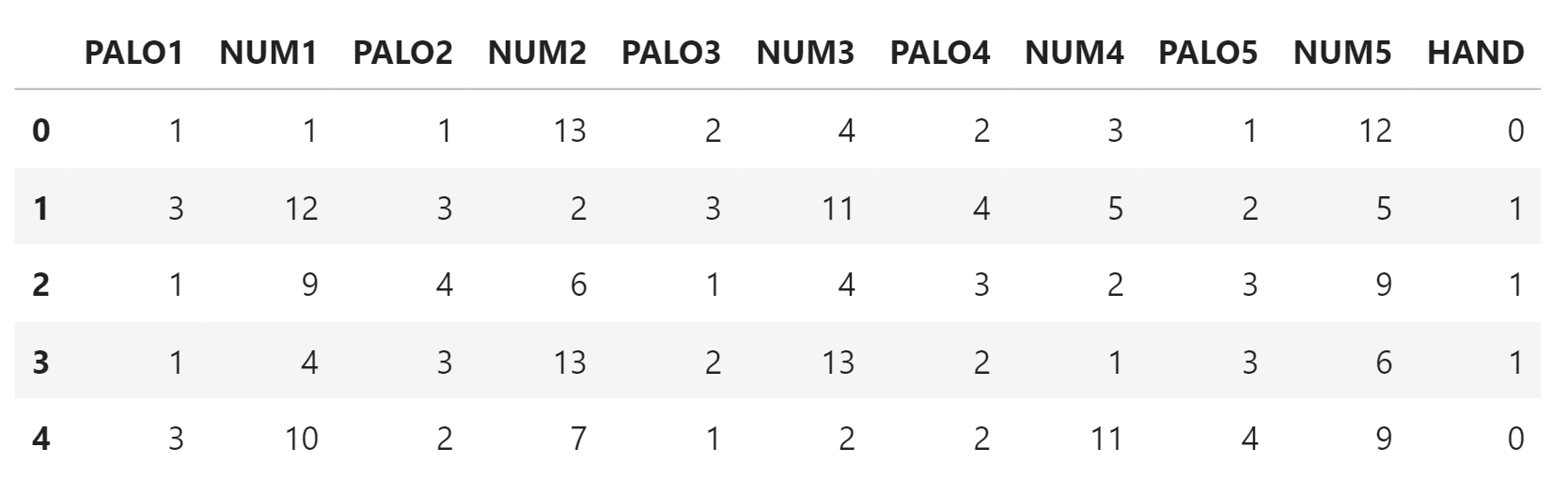
El dataset consiste en un millón de filas correspondientes a un millón de jugadas, y once columnas, el número y color de cada una de las cinco cartas de cada jugadas, así como la columna target que hace referencia a la jugada correspondiente a esas cinco cartas.
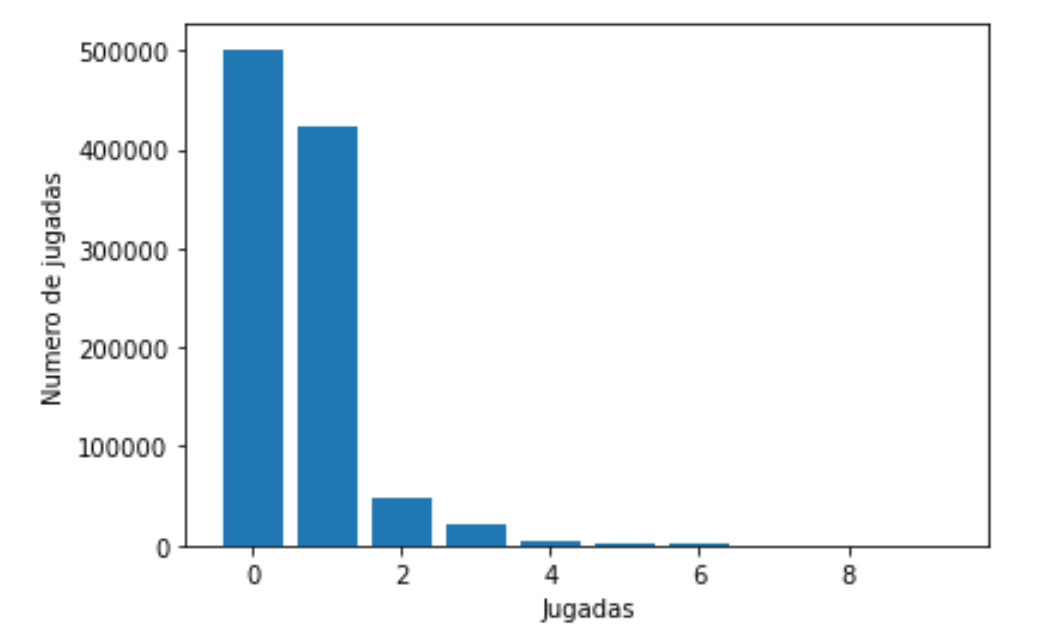
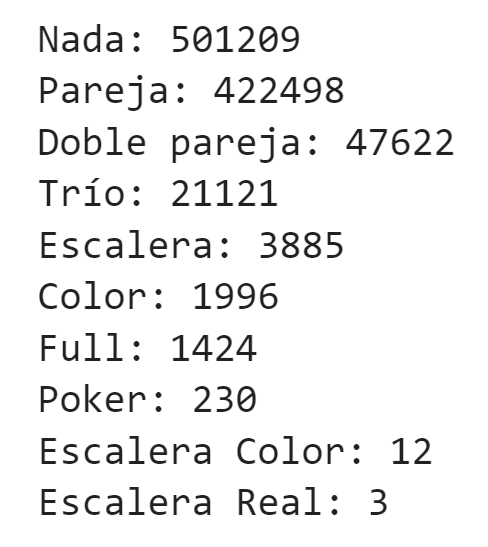
Este dataset presenta dos problemas principales. Por un lado, todas las variables son categóricas. Por otro lado, está extremadamente desbalanceado y solo las dos primeras categorías (jugadas) del target suponen más del 90% de las observaciones, mientras que las últimas categorías no suponen ni el 0,05%.
Modelo utilizado
Para enfrentarnos a este problema de clasificación vamos a utilizar una red neuronal de dos capas ocultas con cien neuronas y apenas diez epochs. A pesar de ser un modelo relativamente sencillo funciona realmente bien.
Transformaciones lineales del dataset
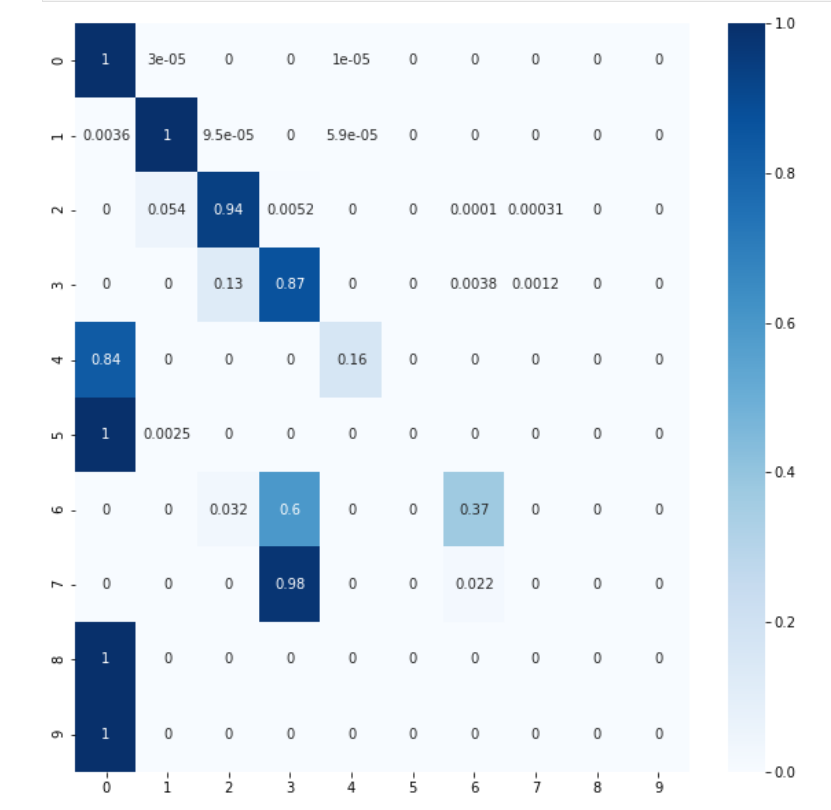
Sin embargo, antes es necesario realizar varias transformaciones del dataset u obtendremos los pésimos resultados al clasificar que se muestran en la siguiente matriz de confusión:
Primera transformación

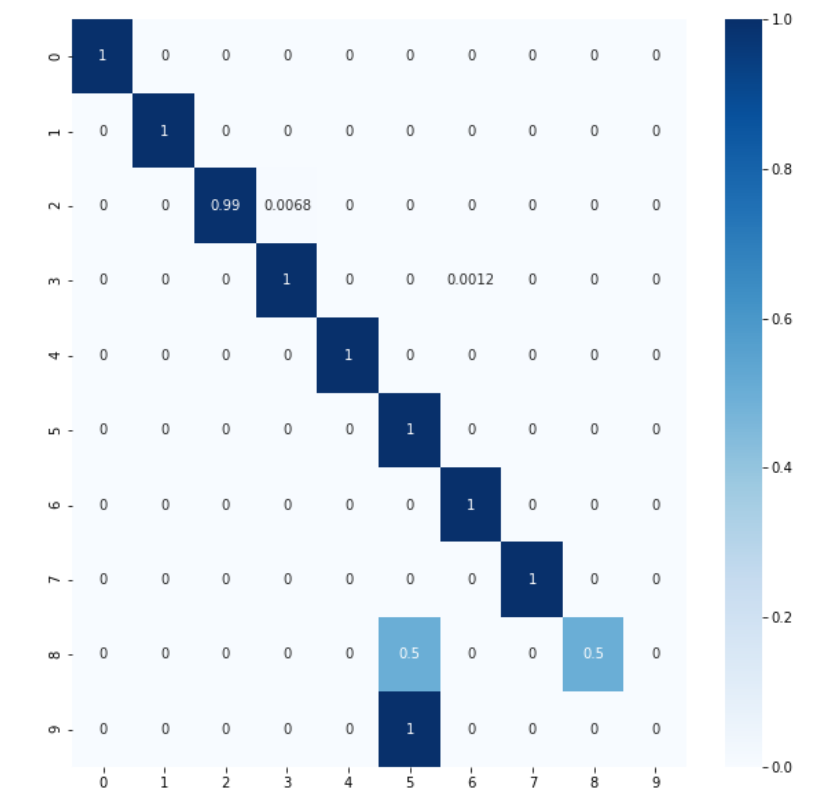
En este primer paso vamos a crear una columna para cada número y cada color de la baraja, cuyos valores serán las veces que aparece dicho número y color en la mano.
![]()
Como podemos observar en la matriz de confusión, la clasificación del modelo ha mejorado notablemente:
Segunda transformación
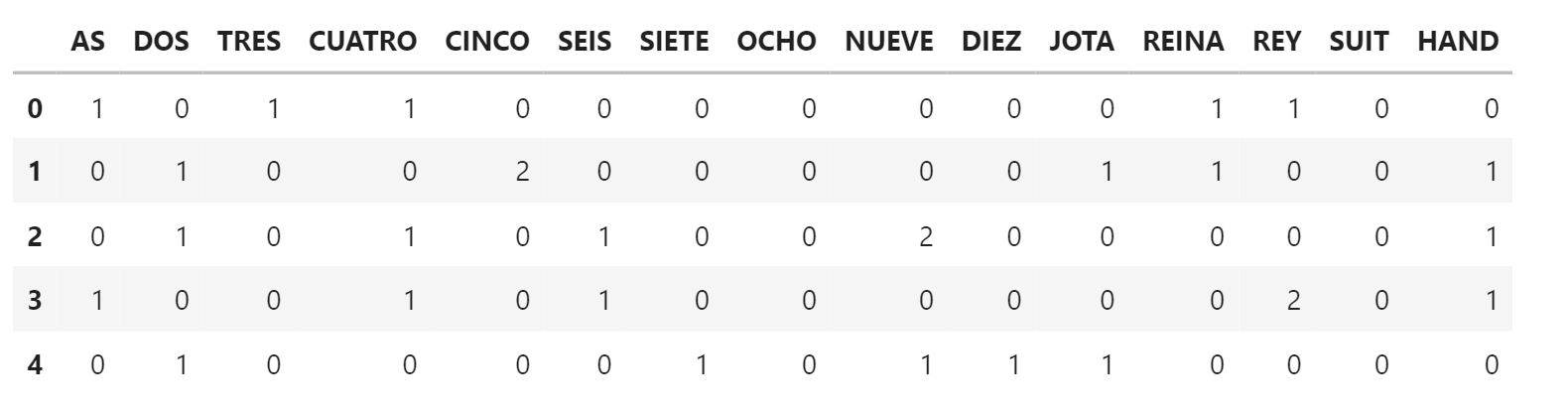
A continuación, sustituimos todas las columnas que hacen referencia al palo de las cartas por una única columna que valdrá 1 si todas las cartas de la mano son del mismo palo y 0 si no lo son.
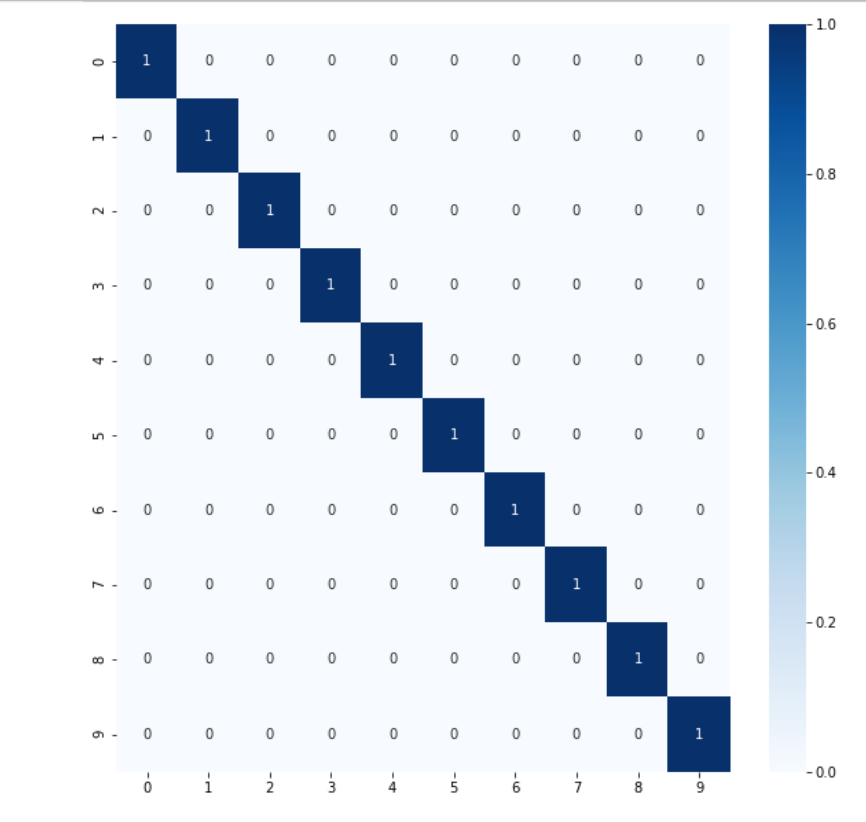
Con esta segunda transformmación del dataset obtenemos un resultado perfecto a la hora de clasificar las jugadas con el modelo:
Por último, probamos el modelo con un dataset extra de 25.000 jugadas igualmente distribuidas que el dataset original y volvemos a obtener una precisión máxima en su clasificación.